
Adres zasobu w sieci to jeden z tych elementów informatyki, które wydają się proste dopóki nie trzeba ich świadomie rozebrać na części. W tym tekście pokazuję, czym jest URL, z czego się składa, jak działa w przeglądarce i kiedy najczęściej sprawia kłopoty. Dorzucam też praktyczne wskazówki, które pomagają pisać czytelne, poprawne i bezpieczne adresy w projektach internetowych.
Najważniejsze rzeczy do zapamiętania o adresie zasobu
- URL to adres, pod którym przeglądarka lub aplikacja odnajduje konkretny zasób.
- Najczęściej składa się ze schematu, domeny, ścieżki, parametrów i fragmentu.
- Adres pełny działa samodzielnie, a adres względny wymaga kontekstu bazowego.
- Znaki specjalne trzeba czasem zakodować, bo inaczej adres może zostać odczytany błędnie.
- Nie każdy technicznie poprawny adres jest dobry dla użytkownika - liczy się też czytelność i bezpieczeństwo.
Co właściwie oznacza adres zasobu w sieci
W praktyce chodzi o zapis, który wskazuje przeglądarce, gdzie znajduje się konkretny zasób: strona, obraz, plik, dokument, a czasem nawet punkt wewnątrz strony. Ja patrzę na to tak: adres nie jest tylko „linkiem”, ale instrukcją, jak dotrzeć do treści i jak ją zinterpretować. To dlatego ten sam mechanizm działa zarówno w przeglądarce, jak i w aplikacjach, skryptach czy systemach serwerowych.
W codziennym użyciu większość osób mówi po prostu o adresie strony, ale technicznie sprawa jest trochę szersza. Taki zapis może wskazywać nie tylko dokument HTML, lecz także zasób w API, obraz używany w materiale edukacyjnym albo plik pobierany przez system. To właśnie ta uniwersalność sprawia, że temat jest ważny dla każdego, kto uczy się podstaw informatyki albo pracuje z webem. Skoro wiemy już, po co taki adres istnieje, pora rozłożyć go na części.
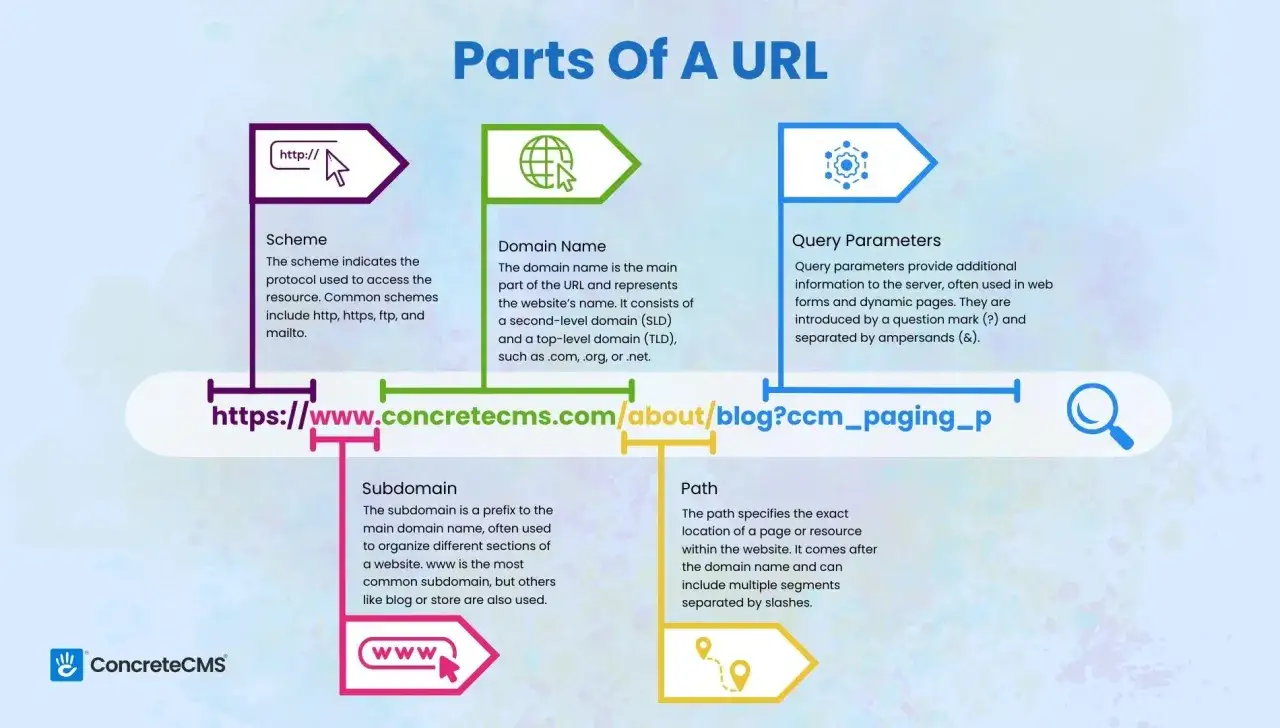
Z czego składa się adres internetowy
Najprościej rozumieć go jako kilka elementów, które razem tworzą pełną instrukcję dotarcia do zasobu. Nie każdy adres musi mieć wszystkie części, ale im lepiej je rozumiesz, tym łatwiej odczytasz i zbudujesz poprawny zapis. Gdy uczę tego tematu, zaczynam od pięciu składników, bo właśnie one pojawiają się najczęściej.
| Część | Co oznacza | Po co jest ważna |
|---|---|---|
| Schemat | Określa sposób dostępu, np. HTTP lub HTTPS. | Mówi przeglądarce, jakiego mechanizmu użyć do pobrania zasobu. |
| Autorytet | Zawiera zwykle domenę, a czasem także port i dane logowania. | Wskazuje, z którego serwera ma zostać pobrana treść. |
| Ścieżka | Opisuje miejsce zasobu na serwerze lub logiczną lokalizację w aplikacji. | Pomaga odnaleźć konkretną stronę, plik albo endpoint. |
| Parametry zapytania | To część po znaku ?, zwykle w formie klucz=wartość. |
Służy do filtrowania, wyszukiwania, przekazywania ustawień lub identyfikatorów. |
| Fragment | Część po znaku #, wskazująca podmiejsce w zasobie. |
Przydaje się do odsyłania do konkretnego nagłówka, sekcji albo pozycji w dokumencie. |
Warto pamiętać o dwóch detalach. Po pierwsze, fragment po # nie trafia do serwera, więc służy głównie na poziomie przeglądarki. Po drugie, port bywa pomijany, jeśli korzystasz ze standardowych wartości dla HTTP lub HTTPS. To właśnie z takich drobiazgów składa się poprawne czytanie adresów w praktyce. Kiedy już rozpoznajesz części składowe, łatwiej zobaczyć, gdzie ten zapis pojawia się na co dzień.
Gdzie adres pojawia się w praktyce
Adresy zasobów nie są tylko elementem paska w przeglądarce. Spotykam je wszędzie tam, gdzie jedna część systemu musi wskazać drugiej, skąd pobrać treść albo dokąd odesłać użytkownika. Dla studenta informatyki to ważne, bo ten sam mechanizm przewija się w HTML, CSS, JavaScript i w konfiguracji aplikacji.
- W linkach HTML, gdy odsyłasz do innej podstrony lub sekcji.
- W obrazach, gdy strona ma pobrać grafikę z serwera.
- W skryptach i stylach, gdy przeglądarka ładuje pliki pomocnicze.
- W formularzach, gdy dane mają trafić do konkretnego endpointu.
- W JavaScript, gdy tworzysz lub analizujesz adres programowo.
Praktycznie ważne jest też to, że nie każdy schemat musi prowadzić do strony WWW. Obok HTTP i HTTPS spotyka się również inne mechanizmy, na przykład do poczty czy zasobów lokalnych. W projektach edukacyjnych i semestralnych najczęściej i tak wracasz do webowych adresów, ale świadomość istnienia innych schematów bardzo pomaga. Kolejny krok to rozróżnienie adresu pełnego od względnego, bo tu najczęściej pojawiają się błędy początkujących.
Adres bezwzględny i względny to nie to samo
To rozróżnienie jest kluczowe, bo od niego zależy, czy adres zadziała samodzielnie, czy tylko w określonym kontekście. Adres bezwzględny zawiera wszystko, co potrzebne do odnalezienia zasobu bez żadnych dopowiedzeń. Adres względny korzysta z adresu bazowego i uzupełnia brakujące części dopiero w momencie odczytu przez przeglądarkę lub aplikację.
| Cecha | Adres bezwzględny | Adres względny |
|---|---|---|
| Pełność | Jest kompletny sam w sobie. | Wymaga kontekstu bazowego. |
| Zastosowanie | Najlepszy do wklejenia w przeglądarce, dokumentacji i komunikacji. | Najwygodniejszy wewnątrz tej samej witryny lub projektu. |
| Odporność na zmianę miejsca | Wysoka, bo wskazanie jest jednoznaczne. | Zależy od tego, gdzie leży plik bazowy. |
| Typowy przykład | schemat://domena/sekcja/plik |
../sekcja/plik albo grafika/miniatura
|
Ja zwykle polecam adresy względne tam, gdzie treść ma żyć wewnątrz jednego projektu i może być przenoszona między środowiskami. Z kolei adresy bezwzględne są wygodniejsze, gdy potrzebujesz jednoznaczności albo odwołujesz się z zewnątrz. Właśnie tutaj przydaje się też informacja o bazie dokumentu, bo to ona decyduje, jak przeglądarka „dopisze” brakujące części. Skoro to już mamy, trzeba jeszcze omówić znak specjalny i kodowanie, bo bez tego nawet dobry zapis potrafi się rozsypać.
Kiedy trzeba zakodować znaki
Nie każdy znak można wpisać do adresu wprost. Część z nich ma znaczenie techniczne, więc jeśli pojawią się w treści jako zwykłe dane, trzeba je zakodować. Najlepiej zapamiętać prostą zasadę: jeśli znak ma w URL-u własną funkcję, a ty chcesz użyć go jako zwykłej litery lub symbolu, zakoduj go.
Najczęściej problem dotyczy spacji, znaków diakrytycznych, ukośników, znaku zapytania, hasza i ampersanda. W praktyce przeglądarki często poradzą sobie z prostymi przypadkami, ale w kodzie i formularzach nie warto liczyć na szczęście. Dla bezpieczeństwa i przewidywalności stosuje się kodowanie procentowe, czyli zapis w stylu %20 zamiast spacji.
-
%20oznacza spację. -
%3Fodpowiada znakowi?. -
%26odpowiada znakowi&. -
%23odpowiada znakowi#.
Jest jeszcze jeden niuans: w danych z formularzy spacja bywa zapisywana jako +, ale nie należy tego mechanicznie przenosić do każdego miejsca. To detal, który często myli początkujących, bo ten sam symbol może oznaczać coś innego zależnie od kontekstu. Gdy rozumiesz kodowanie, łatwiej uniknąć klasycznych błędów i przejść do bardziej uporządkowanego myślenia o nazewnictwie oraz jakości samych adresów.
URL, URI i URN różnią się bardziej teorią niż codzienną praktyką
W codziennej rozmowie większość osób używa słowa URL i to jest całkowicie wystarczające. W teorii jednak spotkasz też pojęcie URI, które jest szersze, bo obejmuje różne typy identyfikatorów zasobów. URN z kolei odnosi się bardziej do nazwy niż do miejsca, czyli opisuje zasób przez identyfikator, a nie przez ścieżkę dostępu.
Dlaczego to w ogóle warto znać? Bo na egzaminach, w dokumentacji i podczas czytania specyfikacji te terminy pojawiają się obok siebie i łatwo uznać je za synonimy. Ja podchodzę do tego pragmatycznie: jeśli pracujesz z internetem, najczęściej myślisz w kategoriach URL; jeśli analizujesz standardy, dobrze mieć świadomość, że URI jest pojęciem szerszym. Taka różnica nie zmienia jednak podstawowej umiejętności, czyli tworzenia czytelnych i poprawnych adresów, a to prowadzi do bardzo praktycznej części tematu.
Jak pisać sensowne i bezpieczne adresy
Tu zaczyna się część, która naprawdę robi różnicę w projektach. Technicznie poprawny adres można zapisać na wiele sposobów, ale nie każdy zapis jest dobry dla użytkownika, zespołu i wyszukiwarki. W praktyce najlepiej działa podejście, w którym adres jest krótki, przewidywalny i nie wymaga zgadywania, co autor miał na myśli.
- Używaj prostych, opisowych nazw zamiast losowych ciągów znaków.
- Oddzielaj słowa myślnikami, a nie podkreślnikami, jeśli tworzysz czytelne ścieżki.
- Unikaj nadmiaru parametrów, jeśli nie służą realnej funkcji.
- Nie umieszczaj danych logowania w adresie, bo to rozwiązanie jest przestarzałe i ryzykowne.
- Zmieniając strukturę serwisu, planuj przekierowania, żeby nie łamać starych odwołań.
W mojej ocenie największy błąd początkujących polega na tym, że traktują adres jak techniczny dodatek, a nie część doświadczenia użytkownika. Tymczasem dobry adres powinien podpowiadać, gdzie prowadzi, a nie tylko spełniać wymóg serwera. To szczególnie ważne w materiałach edukacyjnych, gdzie czytelność ma równie duże znaczenie jak zgodność techniczna. Na koniec zostaje kilka rzeczy, które warto mieć w głowie, gdy zaczynasz pracę z adresami w praktyce.
Co zapamiętać, gdy pracujesz z adresami w projekcie
Jeśli mam zostawić jedną krótką listę do nauki, to właśnie tę: rozbijaj adres na części, sprawdzaj kontekst bazowy, koduj znaki specjalne i nie ignoruj czytelności. Te cztery zasady wystarczają, żeby uniknąć większości problemów na poziomie podstawowym i średnio zaawansowanym.
W praktyce adres zasobu to nie tylko techniczny zapis, ale też sposób porządkowania informacji w internecie. Gdy go dobrze rozumiesz, łatwiej odczytujesz strukturę stron, tworzysz linki, analizujesz dokumentację i projektujesz własne materiały. To jedna z tych kompetencji, które z pozoru są drobne, a potem okazują się fundamentem dalszej nauki. Jeśli chcesz iść krok dalej, dobrze jest ćwiczyć rozpoznawanie części adresu na realnych przykładach i porównywać, jak zachowuje się zapis pełny oraz względny w różnych kontekstach.